Wenn Google, Facebook & Co seit Jahren Daten sammeln und wirtschaftlichen Gewinn machen, dann müssen wir etwas Sinnvolles über das Lernen herausfinden…“
von Margarita Elkina
Tagungsteilnehmer auf der GML 2012
Sie existieren seitdem der erste Lernende seinen digitalen Fuß in eine virtuelle Umgebung setzte; sie sind für Learning Analysten das, was eine unauffällige Fährte einem erfahrenen Scout bedeutet: Daten, die durch die Aktivität von Lernenden im digitalen Raum entstehen. Genau wie ein Fährtenleser Aussagen über Zukunft und Eigenschaften des verursachenden Geschöpfes machen kann, können Learning Analysten u.a. mit Data-Mining Methoden aus Nutzungsdaten Lernstile, Erfolgsprognosen und vieles mehr ablesen.
Im Rahmen des Projektes LeMo ( Lernprozessmonitoring auf personalisierenden und nicht personalisierenden Lernplattformen) stellen wir uns als Ziel, ein Analysewerkzeug zu entwickeln, mit welchem Dozenten, Bildungsanbieter und Wissenschaftler wertvolle Erkenntnisse über das Lernen für Ihre Arbeit gewinnen können.
Als Grundlage für die Forschung dient ein Katalog von über 80 Fragestellungen zum Lernverhalten und zur Mediennutzung der Anwender. Die Anfragen, die verschiedene Nutzergruppen stellen, können in fünf Hauptkategorien eingeteilt werden: Benutzung des Lernangebotes, Performance der Lernenden, Verhalten und Entdeckung von Nutzer-Gruppen, Lernpfade und Nutzung der Kommunikationsangebote. Die Analyse wird mit Methoden des Educational Data Mining geführt. Das Ziel von Educational Data Mining ist, Daten aus Lernsystemen zu untersuchen, um Lernende und deren Lernumgebungen besser zu verstehen.
Die entwickelte Anwendung wird mit geringen Anpassungen auch bei unterschiedlichen eLearning-Plattformen – personalisierend (ein Login ist erforderlich) oder nicht personalisierend (Zugriff ohne Login) – eingesetzt werden können. Eine Besonderheit ist, dass hier Datenanalysen unabhängig von den betreffenden Plattformen und damit plattformübergreifend und –vergleichend erfolgen können. Die verschiedenen Lernplattformen sind sehr unterschiedlich aufgebaut und speichern Daten über das Lernverhalten ihrer Nutzer in verschiedensten Formaten. Personalisierende Systeme nutzen in der Regel Datenbanken zur Protokollierung des Nutzerverhaltens. Bei nicht personalisierenden Plattformen hingegen können Aktionen der Nutzer auch in Log-Dateien gespeichert werden. Um auf diese verschiedenen Datenquellen zugreifen zu können, besitzt das Monitoring-System für jeden Plattform-Typ eine separate Schnittstelle, über die relevante Daten importiert werden. Der Zugriff auf die Daten kann somit erfolgen, ohne dass die Lernplattformen hierfür verändert werden müssen.
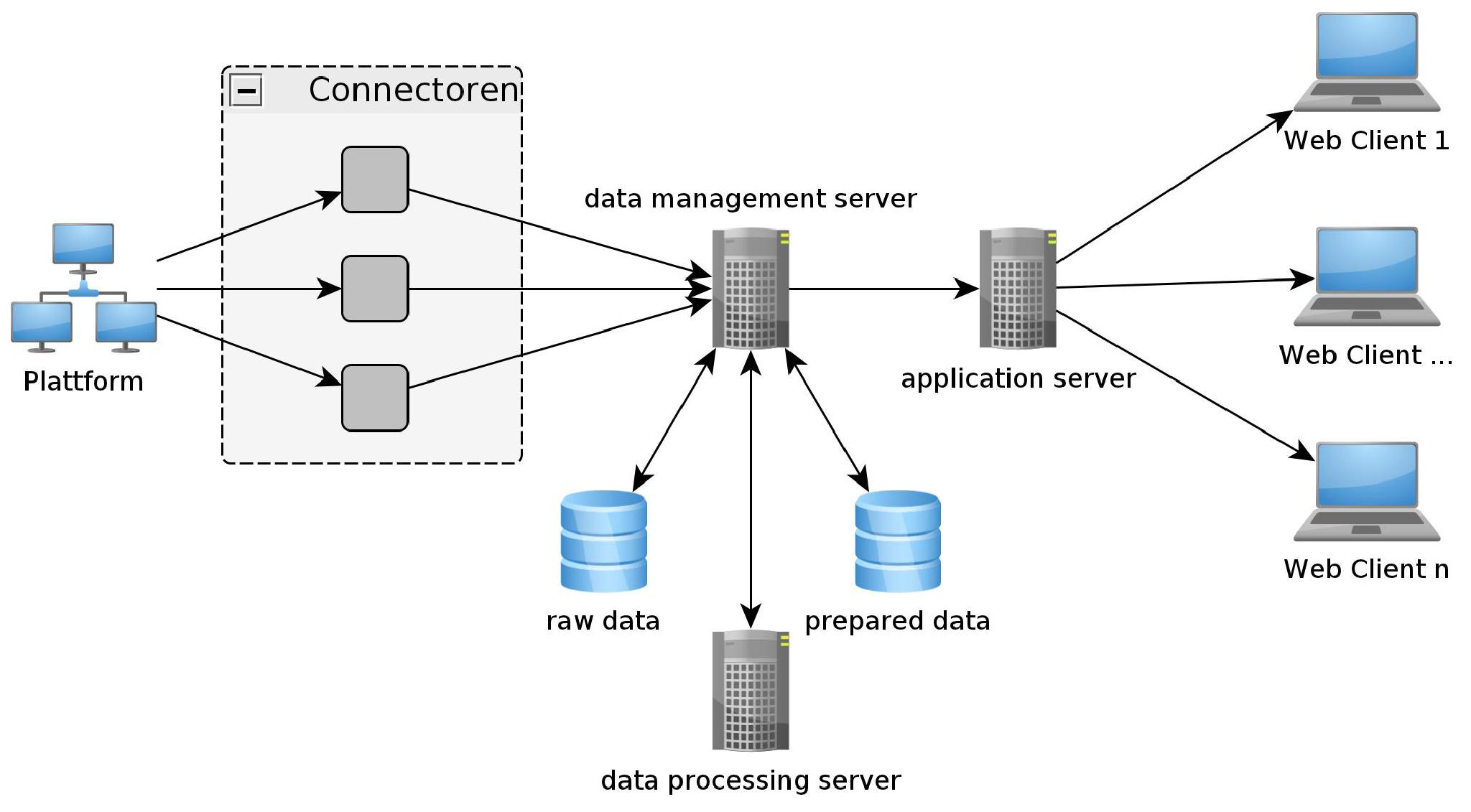
Zu Beginn standen vor allem die technologischen Herausforderungen im Mittelpunkt, z.B. mehrere personalisierende Lernplattformen (Clix, Moodle, etc.) unterstützen zu können und auch Daten Nicht-personalisierender Lernangebote (Plattformen ohne Loginzwang z.B. Chemgapedia) zu berücksichtigen sowie geeignete Möglichkeiten für die Aggregation und Visualisierung von Lernpfaden zu finden. Doch im Rahmen erster Projektpräsentationen wurden wir viel mehr mit ethischen Fragen konfrontiert.
Zum einen stieß die Methodik auf Kritik. Sicher gelten für die Nutzungs-Analysen die Vor- und Nachteile, die generell bei nichtreaktiven Verfahren angenommen werden, doch wirken hier im Lehr-/Lernumfeld neben sachlichen Argumenten auch Vorbehalte bezüglich des Untersuchungsgegenstands selbst, nämlich aus Daten Schlüsse über das Lernen – auf die geistigen Aktivitäten der Nutzer – zu ziehen.
Was erhalten wir durch die Datenanalyse? Statistiken und Bewegungsgraphen werden nach wiederkehrenden Mustern durchsucht, Muster, die interpretiert werden müssen, wobei interpretieren können wir nur dass, was wir wiedererkennen und in Beziehung setzen. Die Interpretation muss auf sinnvollen Modellen fußen und ggf. mit weiteren nicht digital verfügbaren Daten unterlegt werden um die Validität der Ergebnisse nicht zu gefährden.
Zum anderen wurde deutlich, dass Datenschutz nicht nur dem Projekt, sondern auch für die Nutzer ein wichtiges Anliegen ist. Die Gesetzgebung fordert, dass Daten nur ohne Rückschluss auf eine bestimmte Person ausgewertet werden dürfen. Jedoch steht nach kurzer Beschäftigung fest: Vollständige Anonymisierung ist nur schwer zu erreichen. Als Daumenregel gilt, je stärker der Grad der Anonymisierung, desto mehr Daten gehen für die spätere Analyse verloren. Dass alle Bezüge zu Klarnamen aus den Analysedaten entfernt werden, versteht sich hierbei von selbst, für Geburtstage gilt das Gleiche. Doch wie sieht es z.B. mit der Geschlechtszugehörigkeit aus? An sich ließe sich aus der reinen Zuordnung nach männlich und weiblich noch kein Rückschluss auf eine konkrete Person ziehen. Doch wie sieht es aus, wenn die Information zum Geschlecht mit weiteren Informationen kombiniert wird. Etwa einem konkreten eLearning Kurs in dem z.B. nur zwei weibliche Studierende eingetragen sind? Welche Analysen kann das System also zulassen, welche Daten müssen ggf. adaptiv bei der Ausgabe anonymisiert werden? Auf diese und weitere Fragen sollen in den kommenden Monaten Lösungen sowohl technischer Art als auch in Zusammenarbeit mit den zuständigen Datenschutzbeauftragten gefunden werden.
Die zukünftige Entwicklung wird zeigen, in welche Richtungen sich die Analyse von Daten zum Zwecke der Lernforschung entwickelt:
Wird es den Gläsernen Nutzer geben, der bereitwillig mehr und mehr Informationen seiner selbst preisgibt, oder wird der Bedarf nach Anonymisierung obsiegen. Gut denkbar bleibt ein datenschutztechnischer Mittelweg bei dem – wenn man so will – ein semitransparenter Nutzer über die Verwendung seiner Daten in Abwägung zum für ihn subjektiv empfundenen Nutzen selbst entscheiden kann.
Entscheidend für die Frage der Auswertungsmöglichkeiten wird auch sein, wie sich Lehrkonzepte in der Zukunft entwickeln werden. Welche Aktivitäten werden als Lernaktivitäten in Frage kommen? Welche Daten werden dadurch verursacht? Vorstellbar wäre z.B. die stärkere Einbindung sozialer Netzwerke wie Facebook oder Google+. Wie adaptiv können Lernmedien in Zukunft sein? Warum sollten eLearning Plattformen z.B. nicht auch Empfehlungen für weitere passende Lernangebote (vgl. Amazon Buchempfehlungen) anbieten oder auf Wissenslücken für die anstehende Prüfung hinweisen?
Verbesserte Lernangebote helfen den Lehrenden und damit in erster Linie den Lernern selbst. So gesehen könnte aus einem Kompromiss, bei dem beide Seiten Abstriche machen vielleicht sogar eine Situation entstehen, bei der sowohl Lernende wie Analysten gewinnen.
Im Horizon Report 2012 wird Learning Analytics als eine von 6 Schlüsseltechnologien vorgestellt, die in den nächsten Jahren weltweit an Bedeutung gewinnen werden.
Von:
Margarita Elkina, Andreas Pursian HWR Berlin
Liane Beuster, Albrecht Fortenbacher, Leonard Kappe, Boris Wenzlaff -HTW Berlin
Agathe Merceron, Sebastian Schwarzrock – Beuth Hochschule Berlin

0 Kommentare